- 23 Oct, 2023
- read
- Karolinehc
Categories: Ventas Globales Análisis Geoespacial
Tags: Mapeo Geográfico GeoPandas Comercio Electrónico Python Limpieza de Datos Visualización de Datos Fusión de Datos Tendencias de Ventas GeoJSON
El contenido presentado en este artículo está destinado únicamente para fines académicos. Las opiniones expresadas se basan en mi comprensión e investigación personal. Es importante tener en cuenta que el campo de los grandes datos y los lenguajes de programación discutidos, como Python, R, Power BI, Tableau y SQL, son dinámicos y están en constante evolución. Este artículo tiene como objetivo fomentar el aprendizaje, la exploración y la discusión dentro del campo en lugar de proporcionar respuestas definitivas. Se recomienda la discreción del lector.
El ejercicio que se muestra aquí demuestra la importancia de la toma de decisiones basada en datos en el comercio electrónico y cómo los datos y análisis geográficos pueden desempeñar un papel crucial para dirigirse a los consumidores de forma eficaz. Es esencial combinar el análisis de datos con estrategias comerciales para crear estrategias de marketing y ventas exitosas.
Profundicemos en las plataformas en línea que albergan a varios vendedores o proveedores que ofrecen sus productos o servicios y analicemos las ventas para una plataforma donde operan varios vendedores.
Importemos varias bibliotecas de Python, incluidas pandas, numpy, seaborn, matplotlib, statsmodels, random, geopandas, GeoDatraFrame y Punto de geometría bien formada.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from statsmodels.formula.api import ols
import random
import geopandas as gpd
from geopandas import GeoDataFrame
from shapely.geometry import Point
shop1 = pd.read_csv(r'D:\helen\Documents\PythonScripts\datasets\ecommerce\retail1.csv')
shop2 = pd.read_csv(r'D:\helen\Documents\PythonScripts\datasets\ecommerce\retail2.csv', encoding='iso-8859-1')
Limpieza de datos: garantizar la calidad y coherencia de los datos es esencial para tomar decisiones informadas. La limpieza y el preprocesamiento de datos son pasos cruciales antes de realizar cualquier análisis.
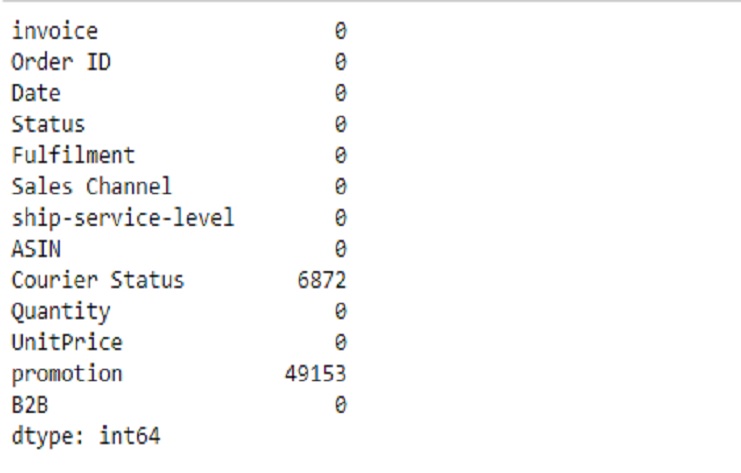
Podemos ver que hay datos faltantes
shop1.isnull().sum()
shop2.isnull().sum()
Tienda1
Tienda2
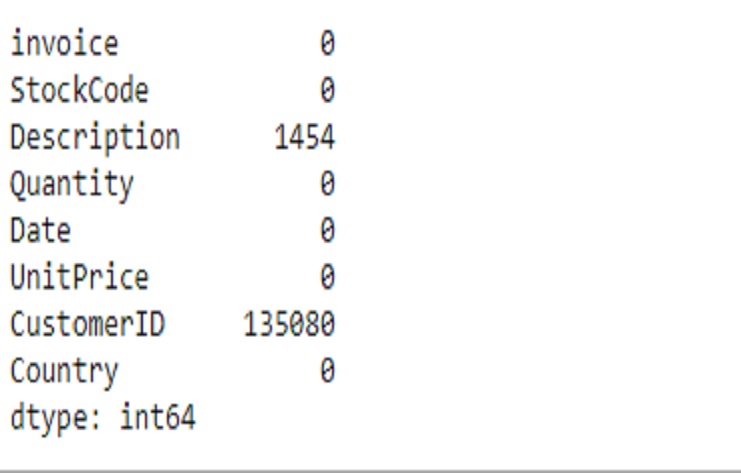
Este código elimina efectivamente las filas con valores faltantes en las columnas “Descripción” y “ID de cliente” y nos proporciona información sobre la nueva forma y la ausencia de valores faltantes en estas columnas. Es una técnica común para el preprocesamiento de datos cuando se trata de datos faltantes.
# List of columns with missing values
columns_with_missing_values = ["Description", "CustomerID"]
# Drop rows with missing values in the specified columns
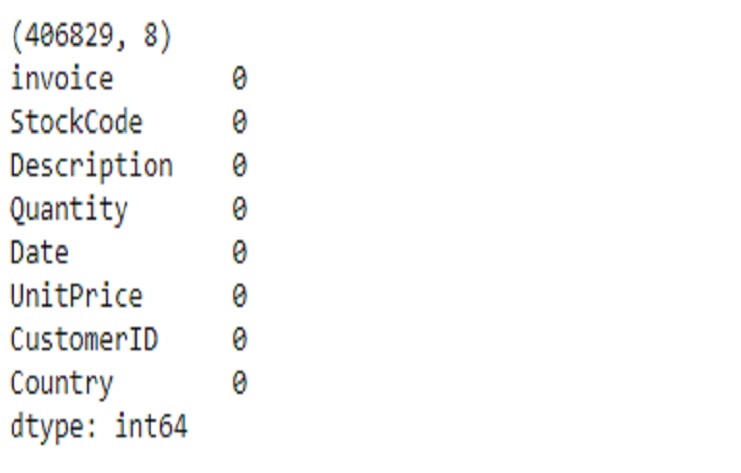
shop2 = shop2.dropna(subset=columns_with_missing_values)
# Verify the updated shape and check for missing values again
print(shop2.shape)
print(shop2.isnull().sum())
No hay valores faltantes ahora
Podemos usar el método .head() para ver las primeras filas de un DataFrame en pandas, lo cual es una excelente manera de obtener una descripción general de los datos y sus columnas.
shop1.head()
shop2.head()
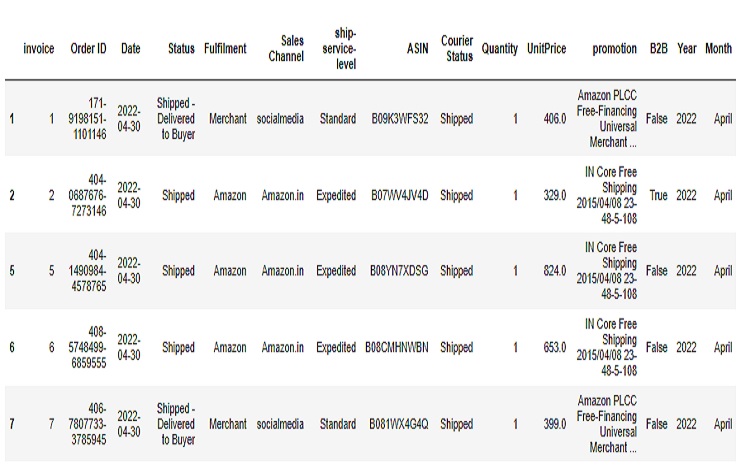
Tienda1 base de datos
Tienda2 base de datos
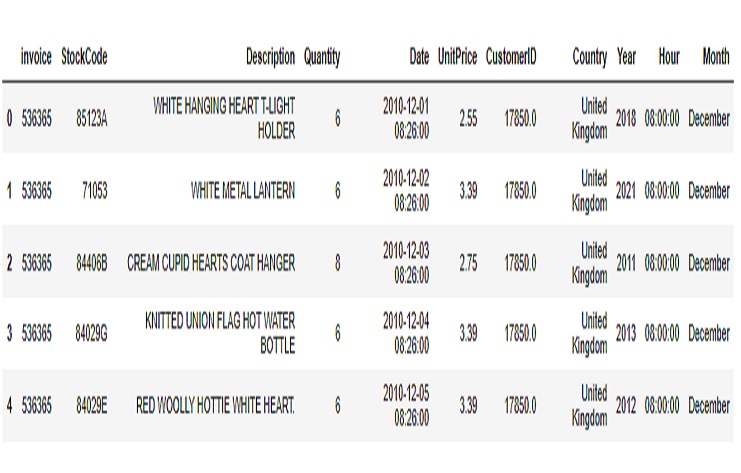
Hay 79822 filas y 15 columnas para el conjunto de datos Tienda1 y 406829 filas y 11 columnas para el conjunto de datos Tienda2
Estamos utilizando la función pd.merge() para fusionar dos DataFrames, Tienda1 y Tienda2, en varias columnas con una unión externa. Esto significa que estamos fusionando los dos DataFrames según las columnas especificadas e incluirá todas las filas de ambos DataFrames, completando los valores faltantes con NaN cuando sea necesario. Luego usaremos el método fillna para reemplazar los valores NaN (Not-a-Number) en nuestro DataFrame con valores específicos de nuestra elección. El método fillna nos permite completar valores faltantes o NaN con otro valor o un conjunto de valores.
shop3 = pd.merge(shop1, shop2_final, on=['invoice', 'Date', 'Quantity', 'UnitPrice', 'Year', 'Month'], how='outer')
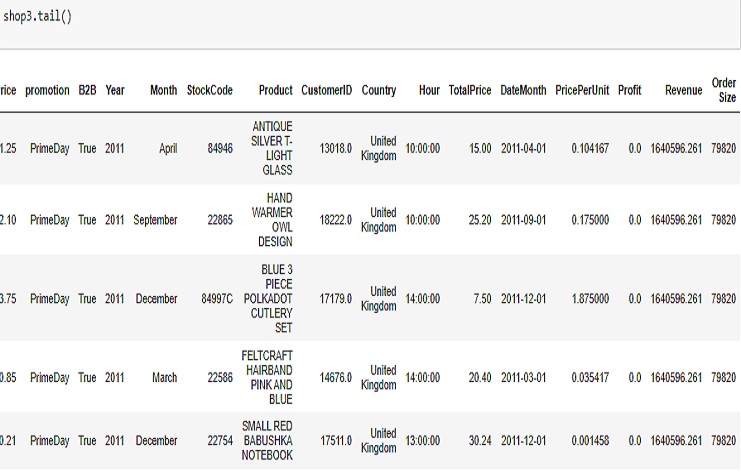
Es útil para inspeccionar rápidamente el final de un DataFrame, especialmente cuando queremos comprobar los datos más recientes o verificar que nuestros datos estén correctamente cargados y estructurados.
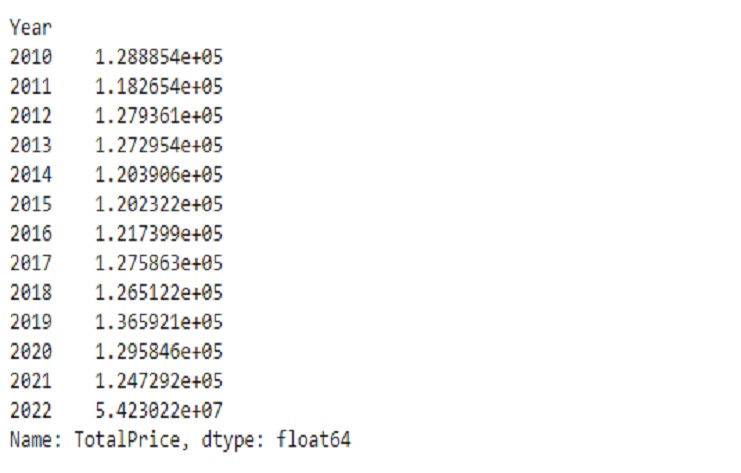
El resultado es una serie Pandas con el año como índice y el monto total de ventas como valores para cada año. Los números se expresan en notación científica debido al formato predeterminado utilizado para números grandes en Pandas. La notación científica es una forma de representar números muy grandes o muy pequeños en un formato conciso.
monthly_year = shop3.groupby('Year')['TotalPrice'].sum()
print(monthly_year)
La columna de la izquierda con años (2010, 2011, 2012, etc.) representa los años para los cuales se calcula el monto total de ventas.
Los valores: la columna de la derecha (por ejemplo, 1.288854e+05) representa el monto total de ventas para cada año correspondiente. En notación científica, “e+05” significa que el número se multiplica por 10^5, por lo que 1,288854e+05 equivale a 128.885,4 (en notación científica, esto se utiliza a menudo para números grandes).
Por ejemplo, en la salida:
En el año 2010, el monto total de ventas es de aproximadamente 128.885,4.
En el año 2011, el monto total de ventas es de aproximadamente 118.265,4.
En el año 2022, el monto total de ventas es de aproximadamente 54,230,220.
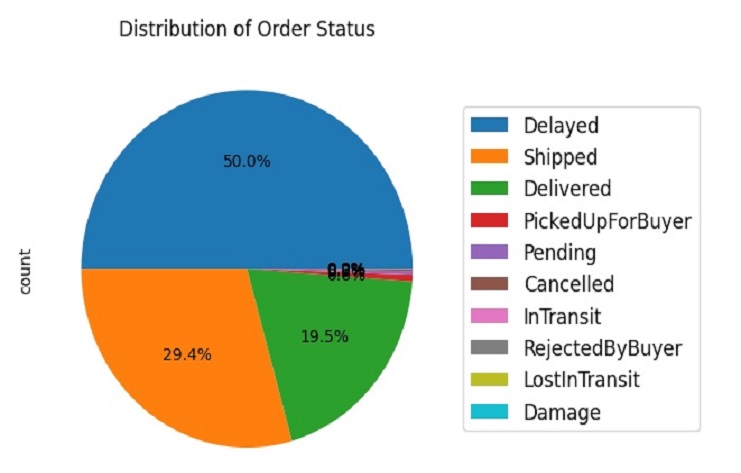
El gráfico circular resultante mostrará la distribución de los estados de los pedidos y la leyenda proporcionará etiquetas para cada porción del gráfico circular. Esta visualización nos ayuda a comprender la proporción de diferentes estados de pedidos en nuestros datos.
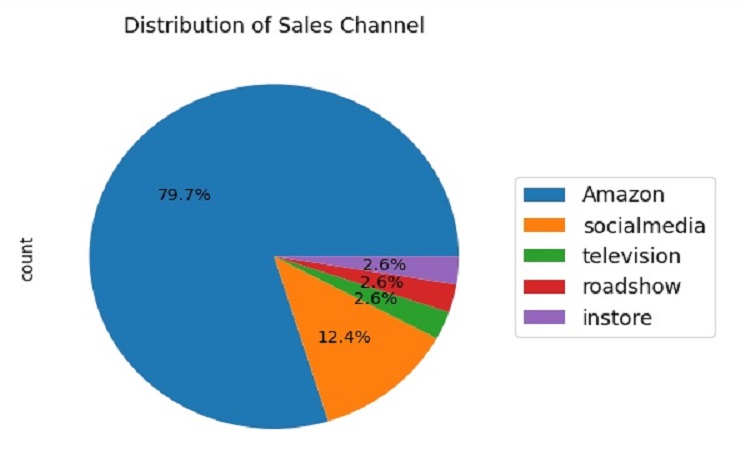
El gráfico circular resultante mostrará la distribución de los canales de ventas y la leyenda proporcionará etiquetas para cada porción del gráfico circular. Esta visualización nos ayuda a comprender la proporción de diferentes canales de ventas en nuestros datos.
Agrupar por
monthly_year = shop3.groupby('Year')['TotalPrice'].sum()
print(monthly_year)
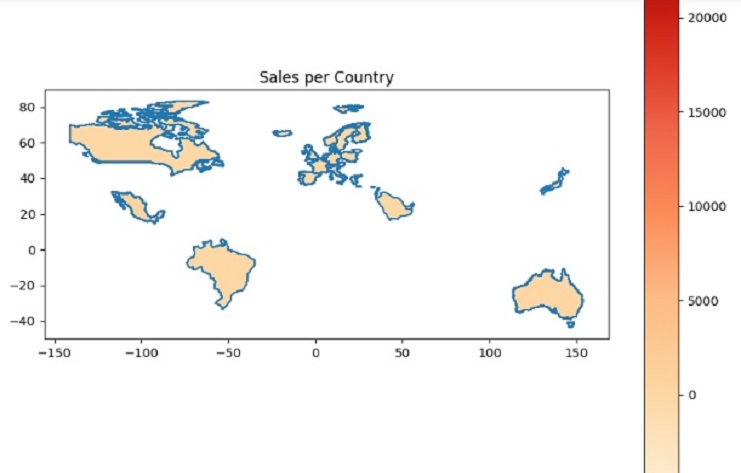
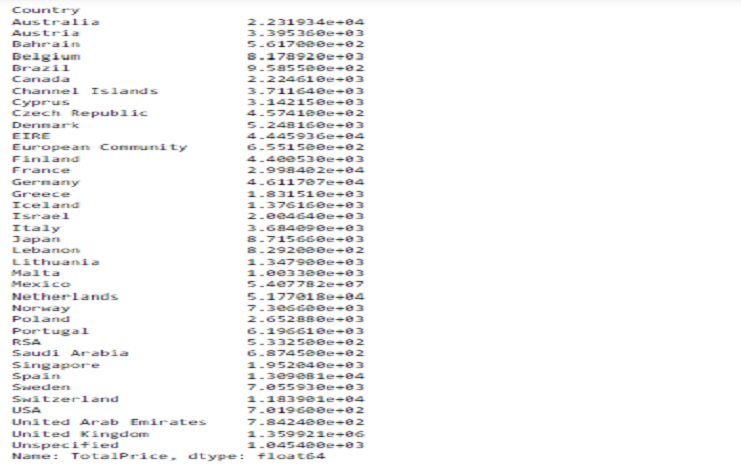
El resultado será una serie donde el índice representa los países únicos en nuestro conjunto de datos y los valores representan las ventas totales de cada país. Esta información puede ser valiosa para analizar el desempeño de las ventas en diferentes países de nuestro conjunto de datos.
Archivo GeoJSON que representa países del mundo.
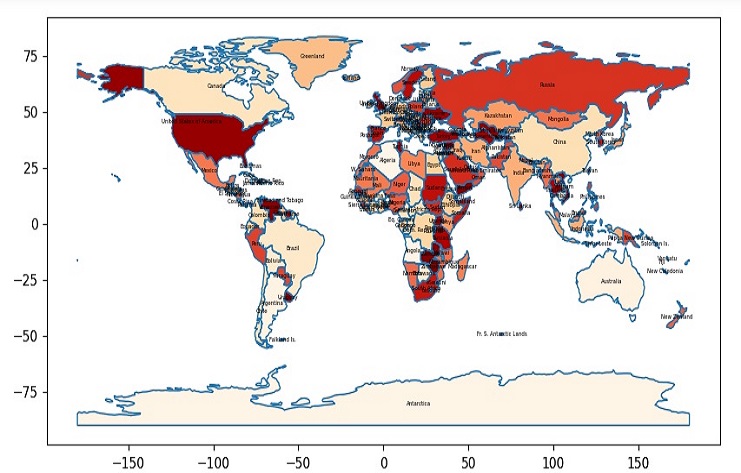
Este código creará un mapa para algunos países y mostrará los datos de “Precio Total”, utilizando el mapa de colores “OrRd”. Podemos personalizar aún más el código para mostrar información diferente o usar un mapa de colores diferente si es necesario.