- 23 Nov, 2023
- read
- Karolinehc
Categories: Análisis de Clientes Proyectos de Comercio Electrónico
Tags: Recencia del Cliente Análisis de Ingresos Pandas Correlación Seaborn Comportamiento del Cliente Visualización de Datos Python
El contenido presentado en este artículo está destinado únicamente para fines académicos. Las opiniones expresadas se basan en mi comprensión e investigación personal. Es importante tener en cuenta que el campo de los grandes datos y los lenguajes de programación discutidos, como Python, R, Power BI, Tableau y SQL, son dinámicos y están en constante evolución. Este artículo tiene como objetivo fomentar el aprendizaje, la exploración y la discusión dentro del campo en lugar de proporcionar respuestas definitivas. Se recomienda la discreción del lector.
Al calcular los “días desde” (puede ser la ultima compra), obtenemos una perspectiva temporal de las transacciones de los clientes, lo que permite una toma de decisiones más informada en áreas como gestión de relaciones con los clientes, marketing y estrategia empresarial.
Comencemos a importar algunas bibliotecas esenciales para el análisis, la visualización y el modelado estadístico de datos. Incluir fecha y hora del módulo datetime en Python es útil para trabajar con datos de fecha y hora.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from statsmodels.formula.api import ols
import random
from datetime import datetime
Cargando los datos
ecommerce = pd.read_csv(r'D:\helen\Documents\PythonScripts\datasets\ecommerce\shop3_CustomerID.csv')
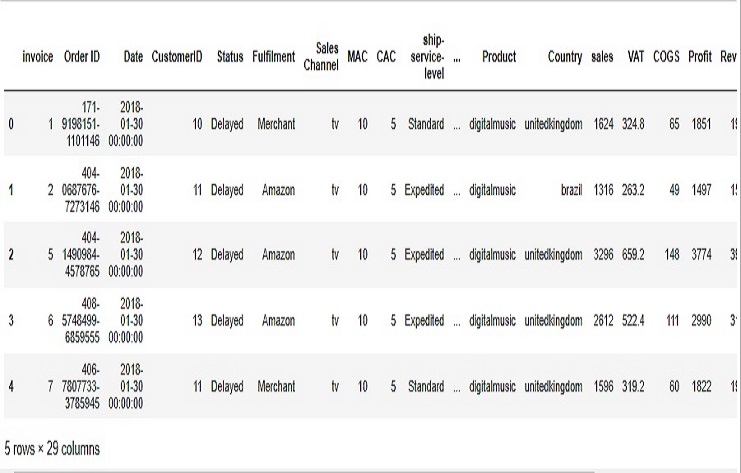
Veamos las primeras líneas de los datos.
ecommerce.head()
Data
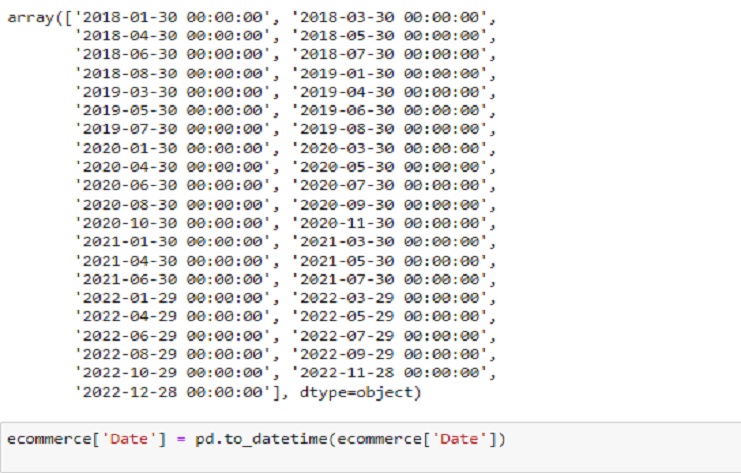
pd.to_datetime
ecommerce['Date'] = pd.to_datetime(ecommerce['Date'])
Usamos pd.to_datetime para convertir una columna a un formato de fecha y hora. El módulo de fecha y hora en Python proporciona funcionalidad adicional para trabajar con fechas y horas, como crear objetos de fecha y hora, realizar operaciones aritméticas y formatear fechas.
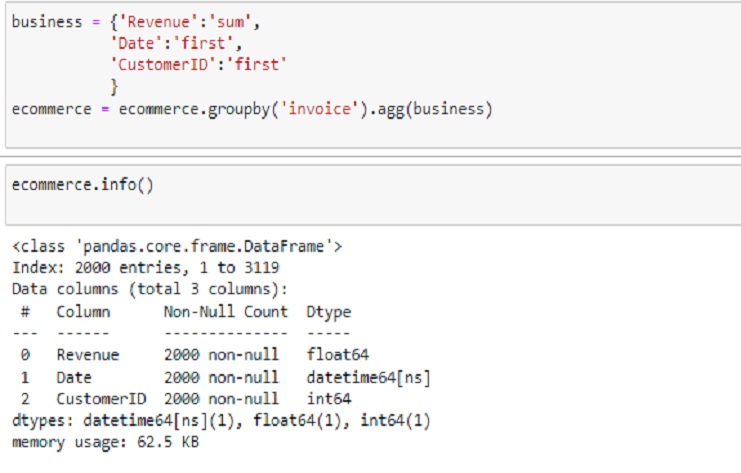
‘Ingresos’:‘suma’: suma los valores de ‘Ingresos’ dentro de cada grupo.
‘Fecha’:‘primero’: toma el primer valor de ‘Fecha’ dentro de cada grupo.
‘CustomerID’:‘first’: tome el primer valor de ‘CustomerID’ dentro de cada grupo
business = {'Revenue':'sum',
'Date':'first',
'CustomerID':'first'
}
ecommerce = ecommerce.groupby('invoice').agg(business)
Informacion
La columna ‘días desde’ resultante representa el número de días entre cada fecha en la columna ‘Fecha’ y el 31 de diciembre de 2018.
ecommerce['Date'] = pd.to_datetime(ecommerce['Date'])
ecommerce['daysince'] = (pd.to_datetime('2018-12-31') - ecommerce['Date']).dt.days
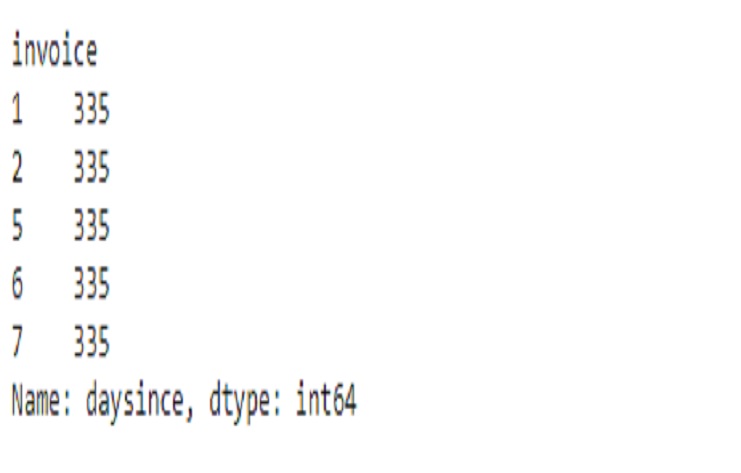
print(ecommerce['daysince'].head())
Es una técnica común utilizada en el análisis basado en el tiempo para medir la actualidad de los eventos en relación con una fecha de referencia específica.
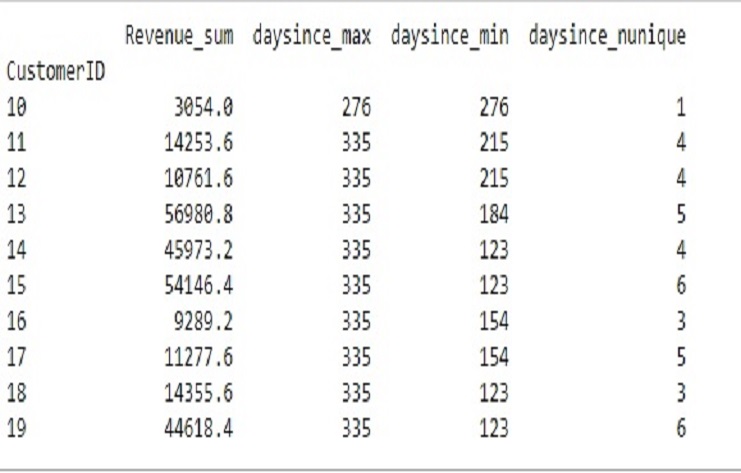
Esta tabla realiza varias operaciones sobre un DataFrame de ’ecommerce’, centrándose en el año 2019.
El resultado final, ‘X’, proporciona información agregada para cada ‘ID de cliente’ en el año 2019, incluida la suma de los ingresos y varias estadísticas relacionadas con la columna ‘días desde’.
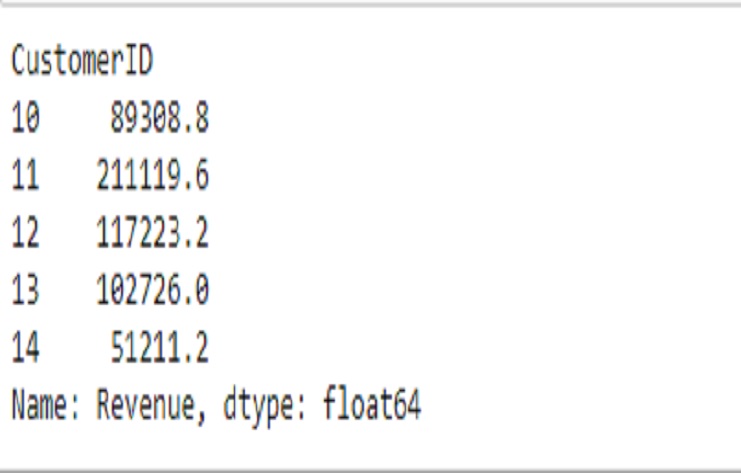
Este fragmento de código filtra el marco de datos de ‘comercio electrónico’ para el año 2022, agrupa los datos por ‘ID de cliente’ y calcula la suma de los ‘ingresos’ de cada cliente.
# Filter the DataFrame for the year 2022
y = ecommerce[ecommerce['Year'] == pd.to_datetime(2022, format='%Y')].groupby('CustomerID')['Revenue'].sum()
# Display the first few rows of 'y'
print(y.head())
La salida es una serie de Pandas con ‘CustomerID’ como índice y la suma de ‘Ingresos’ como valores.
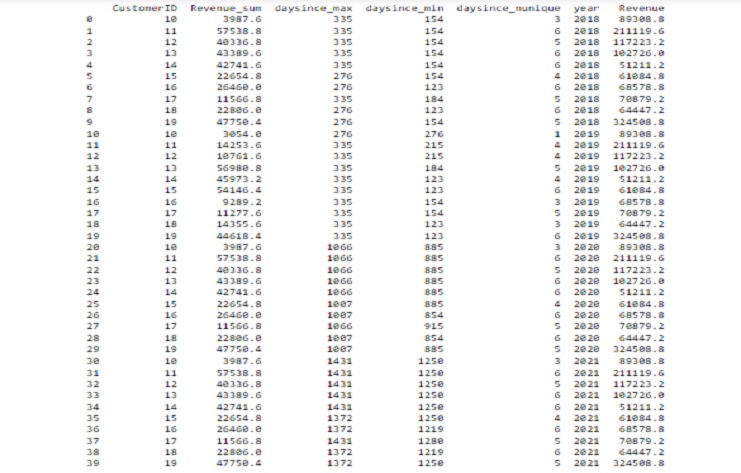
Este fragmento de código combina dos DataFrames, ‘X18192021’ e ‘y’, según la columna ‘CustomerID’ mediante una unión izquierda. Luego muestra las primeras 40 filas de la transacción del DataFrame fusionado.
pd.set_option('display.width', 100) # Adjust the width as needed
pd.set_option('display.max_columns', None) # Display all columns without truncation
# Merge DataFrames on 'CustomerID'
transaction = pd.merge(X18192021, y, on='CustomerID', how='left')
# Display 40 rows of the merged DataFrame
print(transaction.head(40))
El resultado resultante muestra un DataFrame con columnas de ‘X18192021’ e ‘y’, fusionadas en función de la columna ‘CustomerID’.
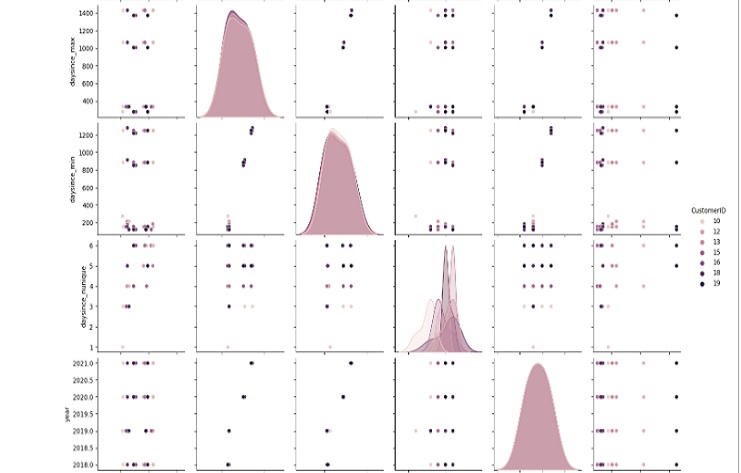
Este fragmento de código utiliza la función pairplot de Seaborn para crear una matriz de diagrama de dispersión por pares para las columnas del DataFrame de ’transacción’.
Cada punto en el diagrama de dispersión representa una fila en el DataFrame, y los diagramas en diagonal muestran la distribución de cada columna individual.
El parámetro de tono está establecido en ‘CustomerID’, lo que significa que se utilizan diferentes colores para diferentes ID de cliente.
El gráfico de pares resultante proporciona una descripción visual de las relaciones entre las columnas numéricas en el marco de datos.
# Use sns.pairplot
sns.pairplot(transaction, hue='CustomerID')
plt.show()
Las correlaciones son relaciones lineales entre dos variables. Pueden ser positivos cuando una variable aumenta y la otra aumenta o negativos cuando una aumenta y la otra disminuye.
La correlación no implica causalidad, y una correlación alta no significa necesariamente una relación causal entre variables.
El coeficiente de correlación varía de -1 a 1.
Los valores cercanos a 1 indican una fuerte correlación positiva (a medida que una variable aumenta, la otra tiende a aumentar).
Los valores cercanos a -1 indican una fuerte correlación negativa (a medida que una variable aumenta, la otra tiende a disminuir).
Los valores cercanos a 0 indican una correlación lineal débil o nula.
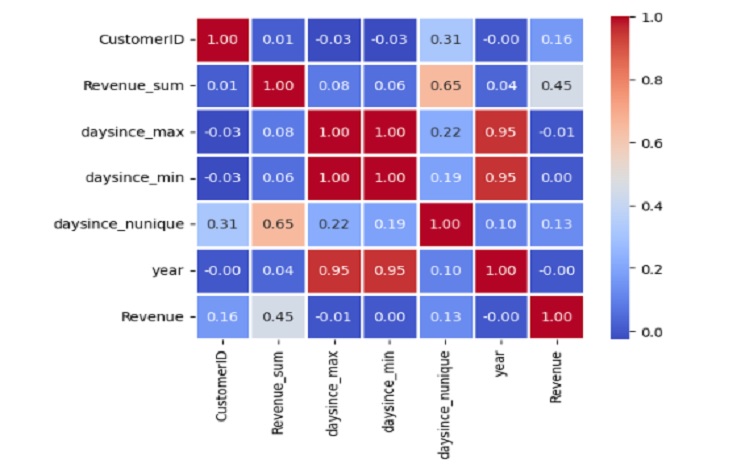
# Display the correlation matrix with annotated values
correlation_matrix = transaction.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f', linewidths=1, square=True)
Correlación positiva entre ‘Revenue_sum’ y ‘year’ (0,046718), lo que sugiere que existe una relación positiva entre los ingresos totales y el año.
Fuerte correlación positiva entre ‘daysince_max’ y ‘daysince_min’ (0,996825), lo que indica que estas dos variables están altamente correlacionadas.
Correlación positiva moderada entre ‘Revenue_sum’ y ‘daysince_nunique’ (0,648330), lo que sugiere que puede haber una relación positiva entre los ingresos totales y el número de días únicos desde la fecha especificada.
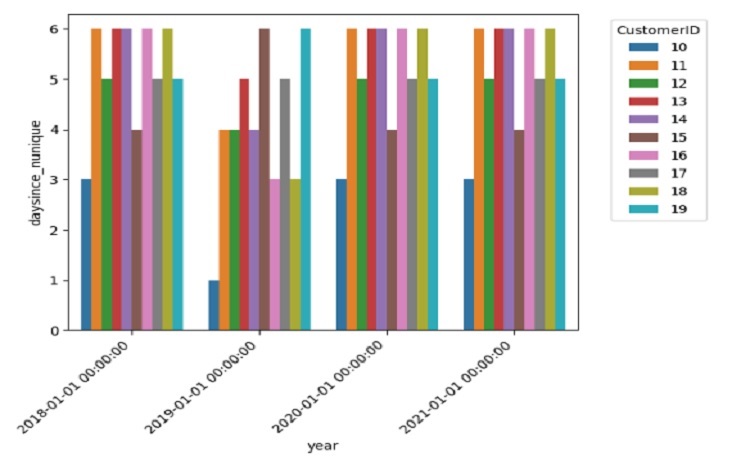
Eje y (‘daysince_nunique’): cada barra representa el número de valores únicos de ‘daysince’ para un ‘CustomerID’ específico. Esto puede darnos una idea de cuántos valores de actualidad distintos tiene cada cliente.
Eje x (‘año’): La gráfica se divide en diferentes años, lo que nos permite observar cómo la distribución de los valores recientes cambia con el tiempo.
Tono (‘CustomerID’): Cada ‘CustomerID’ está representado por un color diferente. Esto nos permite ver cómo varían los valores de actualidad dentro de cada cliente en diferentes años.